Mapping Instructions to Goals for Robot Manipulation via Graph-Structured Energy-Based Concept Models
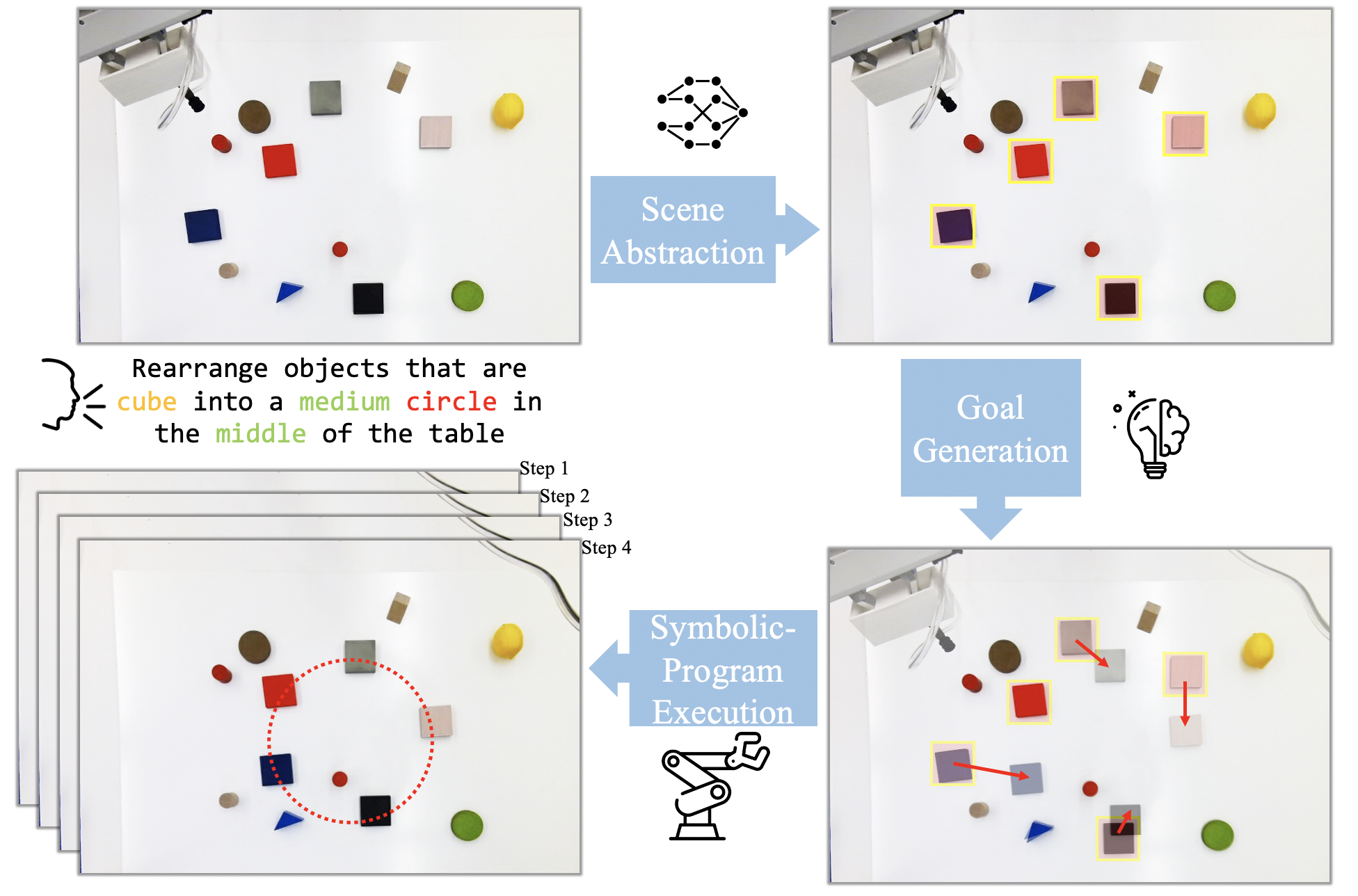
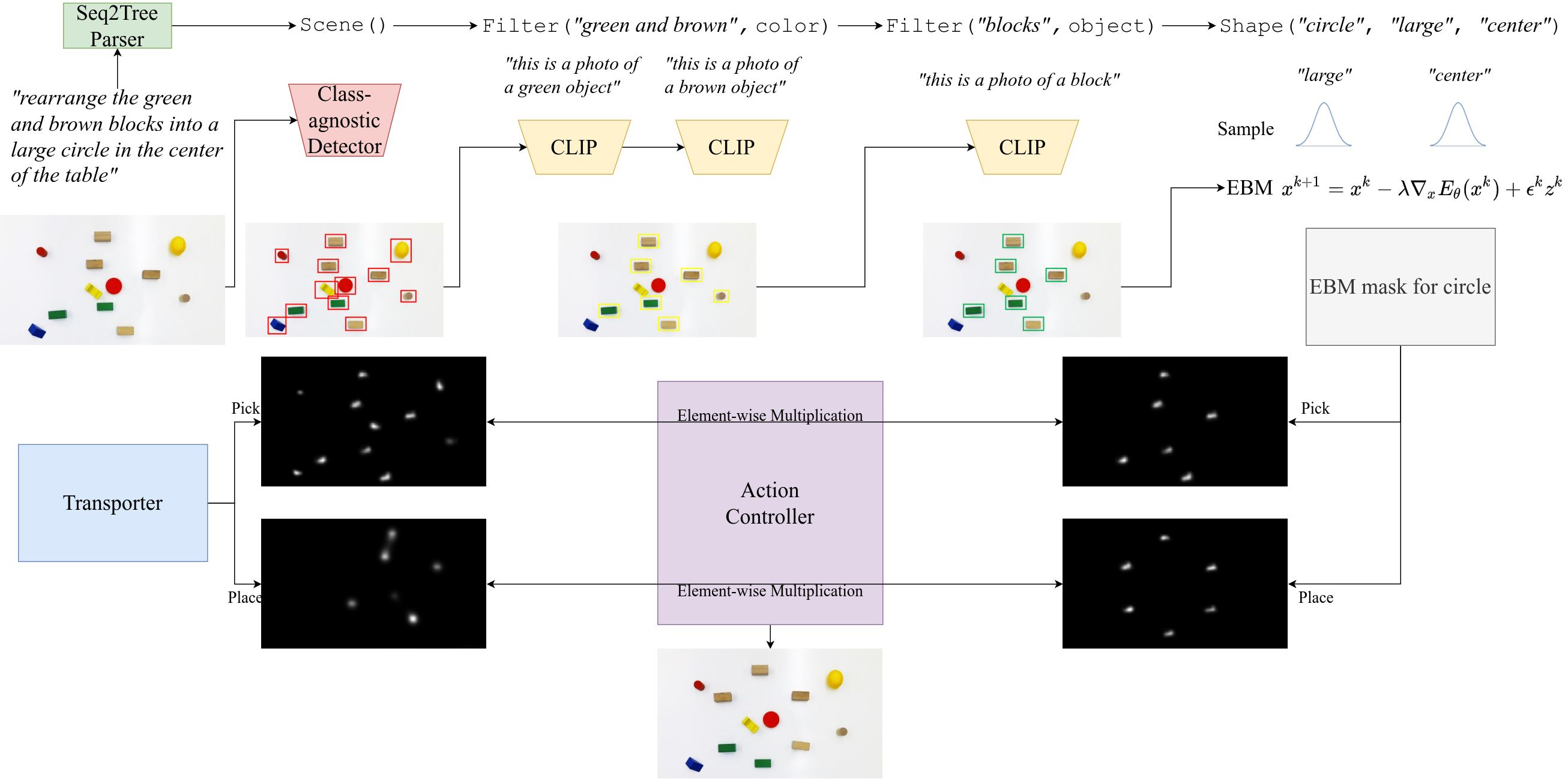
We propose a framework for robot instruction that maps language instructions to goal scene configurations of the relevant object and part entities, and their locations in the scene. The imagined goals modulate the pick and placement locations of a robotic gripper within a transporter network that re-arranges the objects in the scene. Our semantic parser maps language commands to compositions of language-conditioned energy-based models that generate the scene in a modular and compositional way. We show the proposed model can follow instructions zero shot, without ever having seen an instruction (e.g. "make a circle") paired with a set of corresponding actions, by sharing information regarding how objects are picked and placed across multiple different tasks. We show extensive results in simulation and the real world where our agent infers object re-arrangements from language with very little data shared across multiple instruction tasks and outperforms by a margin in out-of-domain generalization existing state-of-the-art language-conditioned transporter works that map language to actions directly. We consistent show dramatic improvements in long horizon manipulation tasks, such as making lines and circles, over existing state of the art image to action mapping methods, as well as in generalization to unseen visual conditions.